So, you want to learn the AWS core concepts in a fast and easy way? Look no further than this guide.
I wrote this post for busy people just like you and me. Most of us are so occupied with modern-life demands that we can not take aside more than 1 hour to develop a new skill (even if this skill can skyrocket your career).
Not to mention the abundance of available material for AWS studies that take months to read through.
With this shortage of time and an overwhelming number of alternatives, confusion about how to start with AWS naturally arises. (The biggest battle is getting people to learn the basics. And that battle is won or lost at a post like this).
By the end of this guide, you will understand the foundational concepts of AWS (and Cloud) + slightly more. (It should not take more than a lunch break to finish the reading).
It doesn’t matter how advanced you are (a total beginner or with some experience ) — everything you need to know is explained so a 5-year-old can understand it.
Cloud is a fancy name for computers that you can use on-demand when you need computational power (and other resources such as storage). To be able to request these resources, you must have an internet connection.
Wikipedia defines cloud computing as the on-demand availability of computer system resources, especially data storage (cloud storage) and computing power, without direct active management by the user.
Wikipedia
Companies that provide these computers (and corresponding hardware and software) are called public cloud providers. The word “public” sits there because these providers make the service publicly available to everyone over the internet.
💡AWS is a public cloud provider. Amazon owns AWS. Other big companies have their public cloud offerings as well — Microsoft has Azure, and Google has GCP.
Public cloud providers
You can visit the AWS website (Public Cloud Provider) and request the resources from your browser directly. AWS will provide a way to connect to these resources (so that you can control them), and you will be charged based on the usage.
So, you rent the computational power from AWS (Cloud provider) like you would rent an apartment and pay the landlord monthly for usage.
In fact, I recommend you to read the entire post on introduction to computer networks when you find some more time — this will help you to understand the high-level picture of how the Internet works. (And how AWS works since AWS is made possible by the Internet).
Amazon is the second largest company in the world (the first is Walmart). Back in the day, Amazon started as an online book store. Since then, Amazon has added many other products, and today you can buy almost anything you can think of on their web store.
In the early 2000s, Amazon started its cloud business by creating AWS (Amazon Web Services). In the beginning, AWS was used for internal purposes within Amazon (to increase the efficiency of the teams). A few years after, Amazon recognized that this business model could generate billions in income and started working toward making AWS publicly available.
Amazon web services
Fast forward some 20 years, and AWS is the biggest public cloud provider that exists today. Amazon’s cloud offering has 33% of the total market share (followed by Microsoft’s Azure with 22%).
AWS now offers more than 200 products that you can rent on demand. However, most of today’s applications use only a few products to make them work. (In this post, I will touch on the most important products only — the rest you can learn easily once you grasp the core concepts).
AWS is the largest cloud provider in existence today. This means that many web and mobile applications use AWS infrastructure. (Probably every second app on your mobile phone runs thanks to AWS).
Also, according to StackOverflow’s yearly survey of more than 70,000 engineers, AWS is the most loved cloud provider.
Given the popularity of AWS, the number of job openings is skyrocketing. (Right now, there are more than 270,000 LinkedIn job openings for AWS engineering roles in the United States — the same trend exists in other countries).
With all this, it is not uncommon that AWS engineers earn on average $122,000 in the United States, and in Europe, cloud engineers earn around €85,000. (These are only averages, the top-paid ones earn close to $200,000 and €120,000).
Suppose the high salary does not motivate you enough. In that case, companies that hire for these positions offer different perks such as paid travel, premium health insurance packages, wellness & leisure budgets, and a company car. (Click here to read my post about engineering salaries abroad).
Due to a huge shortage of AWS engineers, it is a relatively fast process to get a starting position after a few months of practicing your AWS skills.
Lastly, not that obvious, but this field gathers the most intelligent minds of today. Even though you can just be average to start, it matters from who you learn. You will benefit greatly from mere exposure to some of the top-notch guys out there.
Now that you understand that AWS is worth considering for a long-term specialty let’s dig deeper and introduce some AWS-specific parlance.
In this section, you will learn the most important concepts of AWS.
Note: Not all the concepts here relate to an AWS product — some of the concepts explain the core benefits that multiple AWS products share (for instance, scalability). Similarly, all the AWS products share the same philosophy that I want to spend one paragraph explaining.
💡In the core of all the AWS offerings is “you pay for what you use”. The resources are on-demand which means that you do not have to inform AWS about the needed resources in advance. You simply use any amount of these as long as you need them, and once you are done you simply terminate the service (shut it down).
Most of the AWS services run within geographical regions. When you create a service, you will be able to select a geographical region where AWS is going to physically keep the resources that you are renting from them.
AWS regions across the globe (green – already available, red – coming soon)
The full list of the available regions can be found here.
The region selection is important because you want to run your AWS services physically close to your app/website users. The closer the audience is, the faster the speed of serving their requests (better user experience). Read my other article on latency here.
Another important aspect of selecting a region is regional laws. For instance, some banks are allowed to store their data in certain countries only (e.g., a Swiss bank stores the data only in Switzerland).
All the services you buy from AWS run in data centers (read here what servers and data centers are). An availability zone (AZ) is a group of data centers that are physically separated. So, every region consists of multiple availability zones.
One of the most important features of AZs is that they fall independently. If a disaster hits the entire AZ, other AZs of the same region will keep working without interruptions. This is possible because AZs are self-sufficient and contain all the necessary power, cooling, and physical security to feed their existence.
Many real-world projects keep copies of their apps/websites in multiple AZs to ensure that the application is highly available to the users and can survive availability zone failure.
Data centers are buildings within AZ where the physical infrastructure resides. So, data centers contain all the servers, cables, network devices, and other physical security features — the services you are renting from AWS run in those data centers.
Regions, AZs, and data centers are crucial to grasp before you read on since most of the coming paragraphs assume this knowledge. So, read on only when you are ready.
Since AWS is offering its services to millions of customers, there must be a way to separate resources so that every customer can control only their resources.
AWS achieves this with Virtual Private Cloud (VPC). Once you start using AWS products, you will be asked to classify every to a certain VPC.
VPC is only a way to split enormous cloud space into units that individual customers can manage.
💡A useful analogy would be an apartment building split into smaller units (studios) that get rented to tenants.
Within VPC, the resources communicate via private IP addresses (see the full article on IP addressing here). This is similar to your home local network where devices are physically connected.
Resources that belong to the same VPC do not need an internet connection to talk — in the same way, you do not need the connection to order a print job from your local network printer.
VPC is, therefore, a network that is dedicated to a single customer and serves the purpose of logically insulating this customer’s resources from the pool of other owners’ resources.
EC2 is simply a computer that can be commanded remotely (over the Internet).
💡This is the first service that AWS introduced in 2005-2006.
Depending on your needs, you can select all the configurations of an EC2 instance in the similar way you would do when selecting your new laptop’s configuration.
AWS lets you select processor (CPU), RAM, operating system, and storage while creating an EC2. Also, you specify a region and availability zone where this EC2 will be physically hosted (e.g. eu-west-1).
AWS classifies all the EC2 configurations into EC2 types. In that way, there are EC2 types you can select depending on your use case. For example, if your app is using a lot of CPU, you can select some of the CPU-optimized EC2 types, such as c7g.large.
Similarly, there are EC2 types for memory-heavy applications and types for AI-related apps or apps that need a lot of storage.
Once you select the type you need, AWS will set up the machine for you and give you programmatic access (SSH client, browser-based terminal, and AWS CLI).
You can then use the instance as your application requires and install all the software on it. AWS charges you per second for EC2 usage, and you get billed once per month.
💡 EC2 is just a server running on the AWS infrastructure. To understand this concept better, I recommend that you read here what the servers are.
One additional detail to grasp is that EC2 is not a physical server. Behind the scenes, AWS is using virtualization to split one physical computer into more EC2 instances. So, EC2 is a virtual machine (VM) that you rent from AWS. (Read here more about VMs).
Most of the real-world use cases have in their core an EC2 instance. A blog just like this can also be hosted on an EC2 instance that is open for public access. The same goes for mobile apps and any other software that needs computing power. EC2 is nothing more than computing power offered by AWS.
💡As with many other products, AWS offers the “free tier” plan with EC2. This means that you can use their basic EC2 offering at no charge. See here all the Amazon “free tier” offerings.
⚡EC2 is an on-demand (virtual) server you can rent from AWS. Upon selecting a machine type based on your use case, AWS will charge you per second for the usage of this virtual server.
Amazon S3 is a universal storage solution of AWS. When I say universal, I mean that you can store any file type that you want (images, videos, archives).
AWS calls the storage slots the “buckets,” and within these buckets, the individual files reside. (A bucket is, in a sense, a warehouse for virtual objects — files.)
S3 Bucket
S3 buckets integrate nicely with all other AWS products. For example, you can set up a backup of your EC2 instance that gets saved on an S3 bucket. In that way, should something happen to the EC2 instance, the S3 backup is available.
The S3 bucket is a regional concept, and the stored data never leaves the region (this is a regulatory requirement for financial institutions). Also, the name you assign to your bucket must be globally unique.
Besides that, S3 also offers versioning of your objects (files) in a bucket. This means that if you save a file to a bucket and then add new files with the same name, S3 will keep track of all the versions, and you will be able to see all the intermediate states of the file.
💡Objects (files) within a bucket can be opened for global access (over the Internet). The URL format of an object is then similar to this. https://EXAMPLE-BUCKET-NAME.s3.us-west-2.amazonaws.com/MY-PHOTO.png
Most modern apps use S3 buckets to store multimedia. Similarly, my blog could have used an S3 bucket to serve all the images and GIFs in posts. Therefore, S3 is a storage engine of the AWS offering.
💡S3 has different pricing classes depending on how frequently you need access to data (access patterns). The costs of storing data you need most frequently are the highest, and for data you archive and access rarely are the lowest. See here all the AWS S3 storage classes.
⚡S3 is a storage engine of AWS. S3 stores objects within buckets, which is suitable for storing almost any file type (scripts, images, videos, archives).
Almost all websites and apps use databases to store the website’s data. (My blog also uses MySQL database, where WordPress stores all the post texts, comments, categories, and other metadata).
SQL-based (Structured Query Language) databases are the most widespread databases in the world (also known as relational databases).
Due to this popularity, AWS introduced a service that can run a relational database on the cloud — Amazon RDS.
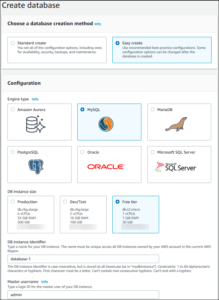
With Amazon RDS, it is possible to choose the database size and the database engine and run an instance that hosts an SQL-based DB directly on the cloud.
💡Instance here is a virtual machine similar to an EC2 instance. The main difference is that RDS instances optimize for data storage and retrieval, whereas EC2 is a more general-purpose VM.
AWS ensures that the latest database engine is running on the instance and that the instance functions properly (AWS handles the management part for you).
Supported database engines
💡Supported database engines: Amazon Aurora, MySQL, MariaDB, PostgreSQL, Oracle SQL, and Microsoft SQL server.
You, as a consumer, only get the database address — URL (with credentials) so that you can use the database in your application’s code. (Your application writes to the database by connecting to it first).
Once you create an AWS account, you will be granted so-called root user credentials. This root user has all the permission, and no one can limit the root user’s rights. (For instance, the root user can delete the entire AWS account and change the billing details or the email).
Because of this huge responsibility, the root user’s credentials are usually locked away, and in practice, companies use AWS IAM to manage the AWS account.
In IAM, you can create users and assign the permission level that their role assumes. For example, a user can only see the available EC2 instances but not create a new EC2. Or, a user can access only the billing-related services but cannot access S3 buckets or EC2 instances.
The IAM users login to AWS with their username (email) and password and can use all the AWS resources to the extent granted to them by the root user (via an IAM policy).
IAM is the user management platform through which AWS account administrators can enforce the least privilege principle (always grant the lowest possible permissions needed for a task).
💡You might not see the knowledge about IAM as the most relevant. This is true especially if you are just starting and you will not have other users to manage. However, it is important to keep the principle of the least privilege in mind as you progress in your AWS skills. This principle is at the core of all AWS products. To set yourself on a good path, store your root user’s credentials somewhere safe and create an IAM user with admin rights that you can use to log in.
⚡IAM is a platform to manage users and their access within an AWS account. With IAM, you can create new login credentials and grant the desired level of access to those users so that every user sees only the AWS resources in their scope of responsibility.
As with all other AWS products, CloudFront resolves a particular problem.
When you access any website, the time you will be waiting for the website to load fully depends on how far the servers that store the website are. The farther the geographical distance, the longer it takes the electrical signal to travel and the longer the waiting time. (Read my other post on computer networks and server latency).
AWS CloudFront resolves the problem of geographical distance between website visitors and the servers (for instance, EC2). The way CloudFront manages this is very simple: keep a copy of data physically close to the website visitors. (The copy is also called a cache).
These copies of data reside in some of the worldwide data centers of AWS (also called edge locations).
To explain CloudFront better, let’s look at an example. I might have an EC2 instance + an S3 bucket (to host my website) located in Dublin, but after some time, I might realize that I get a lot of visitors from Japan. Due to the geographical distance, my visitors from Japan will wait longer to get the website fully loaded (e.g., images, CSS, and js). In this case, I could use CloudFront and store a copy of my website’s images and scripts in an edge location in Japan. This will make the website load very fast regardless of the actual location of my S3 bucket and EC2.
💡CloudFront works closely with EC2, S3, or another service because the edge location holds only a copy of data while the original (that can change/get deleted) is stored in an EC2 or S3. Therefore, there is a regular synchronization between these AWS products.
⚡CloudFront is a CDN (Content Delivery Network) by AWS. It stores a copy of data (a cache) from an S3 (or another source) close to the visitor so that the visitor does not wait too long for the resource to load.
Whenever one needs virtual servers, it is almost always because the person needs to run some code. AWS’s Lambda takes this need of “running the code” to the next level.
AWS Lambda introduces so-called serverless computing. This means you can upload your code to AWS Lambda, specify conditions for triggering the code, and pay only when your code is running.
💡Note: the word “serverless” is here to stress that you do not have to worry about the physical infrastructure that runs your code. Do not think mistakenly that the code can run without servers.
You can set the code to trigger based on certain conditions. (If you want to learn to code, read my beginner’s Python guide). For instance, run a function once a new photo gets added to an S3 bucket. Similarly, the code can start in response to an API call (HTTP) or to a new row that is added to an SQL-based database.
So, your code is a response to an event (trigger). This microservice-based architecture has been very prominent in the last couple of years, and it will continue to dominate in the years to come. Because of this, AWS has been investing heavily in AWS Lambda and the concept of serverless computing.
At the end of the month, you pay only for the time your code ran. AWS measures this on the scale of milliseconds.
⚡AWS Lambda lets you run your code without worrying and provisioning any infrastructure. This service is also called serverless computing service because you, as a customer, do not care about the underlying infra (you are only interested in your code execution).
Easy scaling is at the core of all AWS services. Amazon recognized early that the need for servers (and infrastructure in general) vary depending on the business needs. For instance, an umbrella web store will have much more traffic in the autumn/winter months compared to the summer months (which reflects their business cycle).
Most companies that use AWS fall under the same basket — their business cycle dictates the need for servers, storage, and network.
With AWS, it is now easy to adjust the infrastructure that runs your app/website, depending on the business cycle.
This also brings a lot of savings compared to the pre-cloud era when one needed to commit to a certain usage level for at least one year (and pay for it upfront).
In engineering, scaling up and scaling out are typical responses to traffic growth. You scale up when you want to replace one server with another stronger and more performant (e.g., has more RAM, CPU). (NOTE: after the replacement, it is still one server).
In contrast, scaling out happens when you add more servers (next to the existing ones) so that the traffic gets distributed across all the servers evenly. After the replacement, you have more units that serve the requests.
All the services we discussed here allow seamless scaling up and scaling out. If you create an EC2 instance that, over time, becomes too weak to support your website, you can always change the instance type in a few button clicks (scale up).
AWS Lambda brings this auto-scaling concept even further since Amazon is promising an infinite amount of requests that you can make to your Lambda functions (auto-scaling triggers in the background without you configuring anything).
When the traffic reduces, you can easily terminate the resources you no longer need and avoid charges. This is one of the cloud computing greatest benefits.
⚡All AWS services already embed auto-scaling. This is at the core of AWS. It simply means that you can add more resources to support your website traffic with a few button clicks. With minimal or no downtime. Once you do not need the resources any longer you can decommission them and stop paying for them — all this on-demand, without any notice period.
Congratulations on reading all the way through. It was long writing, and you learned a bunch of new things.
Before the final words, let’s summarize what we have learned.
Cloud is just a fancy word, and physical resources are in the background. Public cloud companies own these resources and rent them further to the public (over the Internet).
Of the current public cloud providers, Amazon’s AWS is the biggest based on market share. Also, there is a significant shortage of cloud engineers that companies are trying to reduce with great salaries and perks.
I spent considerable time covering the core AWS products, the main ingredient of 90% of deployments I worked on. So, we touched on EC2, S3, RDS, IAM, CloudFront, and Lambda.
Next, I explained VPC, auto-scaling, and regions/availability zones. This together makes a great foundation for further learning.
I am going to write more on the cloud subject. Meanwhile, you can subscribe to my newsletter to stay tuned and receive the latest articles in your inbox (I also write sometimes only for my email list members, so make sure to subscribe as some posts are not public).
Share any comments or questions, and I will see you shortly in my email list or another blog post.
Experienced tech professional with a strong track record in web services and fintech. Collaborating with Silicon Valley's multi-billion tech giants and offering a range of services committed to excellence. Check the Services page for how I can help you too.










")
![How To Choose The Best Programming Language To Learn For Beginners [Programmer’s Guide]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%20150%20150'%3E%3C/svg%3E "How To Choose The Best Programming Language To Learn For Beginners [Programmer’s Guide]")
")


")

![How To Choose The Best Programming Language To Learn For Beginners [Programmer’s Guide]](https://igorjovanovic.com/wp-content/uploads/2022/10/front_office_department-300x197.png "How To Choose The Best Programming Language To Learn For Beginners [Programmer’s Guide]")
")


One reply on “AWS Learning Path For Beginners: How to Master AWS in lunch break [FREE]24 min read”
Excellent!